1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
| from pwn import *
alphabet = "0123456789abcdef"
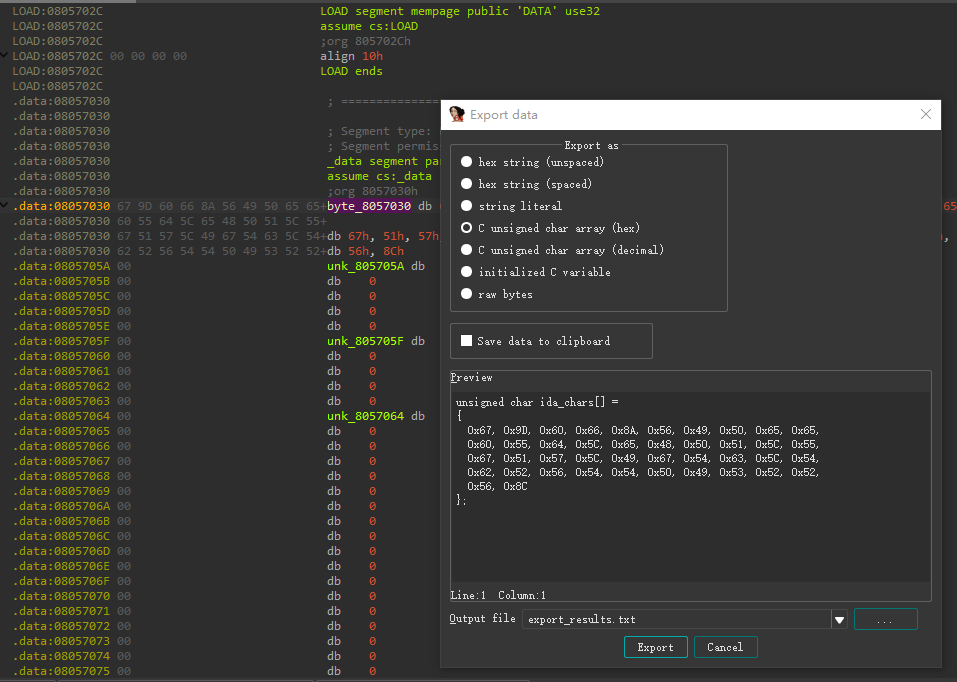
raw = [0x67, 0x9D, 0x60, 0x66, 0x8A, 0x56, 0x49, 0x50, 0x65, 0x65,
0x60, 0x55, 0x64, 0x5C, 0x65, 0x48, 0x50, 0x51, 0x5C, 0x55,
0x67, 0x51, 0x57, 0x5C, 0x49, 0x67, 0x54, 0x63, 0x5C, 0x54,
0x62, 0x52, 0x56, 0x54, 0x54, 0x50, 0x49, 0x53, 0x52, 0x52,
0x56, 0x8C]
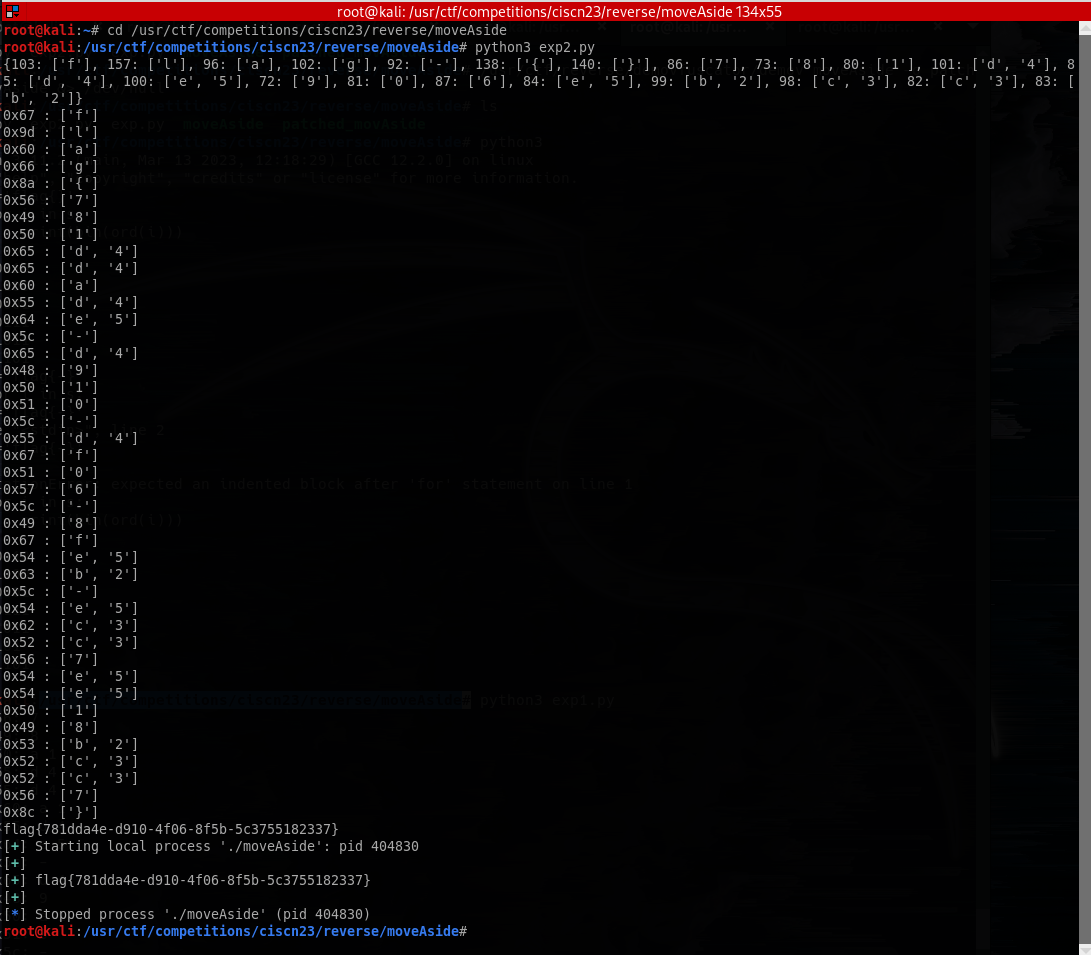
d = {0x67: ["f"], 0x9d: ["l"], 0x60: ["a"],
0x66: ["g"], 0x5c: ["-"], 0x8a: ["{"], 0x8c: ["}"]}
for j in range(5, 41):
if raw[j] in d.keys():
continue
t = []
for i in range(1, 256, 2):
s = chr(raw[j] ^ i)
if s in alphabet and ord(s) & 0xe == raw[j] & 0xe and s not in "flag{-}":
t.append(s)
d[raw[j]] = t
print(d)
for i in raw:
print(f"{hex(i)} : {d[i]}")
ds = [
{0x63: 'b', 0x53: '2', 0x62: 'c', 0x52: '3', 0x65: 'd', 0x55: '4', 0x64: 'e', 0x54: '5'},
{0x63: 'b', 0x53: '2', 0x62: 'c', 0x52: '3', 0x65: 'd', 0x55: '4', 0x64: '5', 0x54: 'e'},
{0x63: 'b', 0x53: '2', 0x62: 'c', 0x52: '3', 0x65: '4', 0x55: 'd', 0x64: 'e', 0x54: '5'},
{0x63: 'b', 0x53: '2', 0x62: 'c', 0x52: '3', 0x65: '4', 0x55: 'd', 0x64: '5', 0x54: 'e'},
{0x63: 'b', 0x53: '2', 0x62: '3', 0x52: 'c', 0x65: 'd', 0x55: '4', 0x64: 'e', 0x54: '5'},
{0x63: 'b', 0x53: '2', 0x62: '3', 0x52: 'c', 0x65: 'd', 0x55: '4', 0x64: '5', 0x54: 'e'},
{0x63: 'b', 0x53: '2', 0x62: '3', 0x52: 'c', 0x65: '4', 0x55: 'd', 0x64: 'e', 0x54: '5'},
{0x63: 'b', 0x53: '2', 0x62: '3', 0x52: 'c', 0x65: '4', 0x55: 'd', 0x64: '5', 0x54: 'e'},
{0x63: '2', 0x53: 'b', 0x62: 'c', 0x52: '3', 0x65: 'd', 0x55: '4', 0x64: 'e', 0x54: '5'},
{0x63: '2', 0x53: 'b', 0x62: 'c', 0x52: '3', 0x65: 'd', 0x55: '4', 0x64: '5', 0x54: 'e'},
{0x63: '2', 0x53: 'b', 0x62: 'c', 0x52: '3', 0x65: '4', 0x55: 'd', 0x64: 'e', 0x54: '5'},
{0x63: '2', 0x53: 'b', 0x62: 'c', 0x52: '3', 0x65: '4', 0x55: 'd', 0x64: '5', 0x54: 'e'},
{0x63: '2', 0x53: 'b', 0x62: '3', 0x52: 'c', 0x65: 'd', 0x55: '4', 0x64: 'e', 0x54: '5'},
{0x63: '2', 0x53: 'b', 0x62: '3', 0x52: 'c', 0x65: 'd', 0x55: '4', 0x64: '5', 0x54: 'e'},
{0x63: '2', 0x53: 'b', 0x62: '3', 0x52: 'c', 0x65: '4', 0x55: 'd', 0x64: 'e', 0x54: '5'},
{0x63: '2', 0x53: 'b', 0x62: '3', 0x52: 'c', 0x65: '4', 0x55: 'd', 0x64: '5', 0x54: 'e'},
]
for i in range(16):
flag=''
for j in raw:
if len(d[j])==1:
flag+=d[j][0]
else:
flag+=ds[i][j]
print(flag)
proc=process('./moveAside')
proc.sendlineafter(b'flag:\n', flag.encode())
proc.recvline()
res = proc.recv(timeout=0.02)
if b'yes!' in res:
success('\n')
success(flag)
success('\n')
exit(0)
proc.kill()
|